Spark 引擎
原理解释
Spark 引擎是基于 Spark 开发的数据质量检查作业执行引擎,SparkDataVinesBootstrap 是应用的执行入。Datavines 会根据用户所配置各种信息构造成配置文件并传入到 SparkDataVinesBootstrap中,SparkDataVinesBootstrap 会解析配置文件并选择不同的 source、transform 和 sink 插件来执行连接数据源、质量检查语句和将执行结果写入到相应的存储引擎中的操作。
使用方法
在数据质量检查作业和数据比对作业中的引擎配置中选择 Spark 引擎,填好各种 Spark 相关的基础配置信息
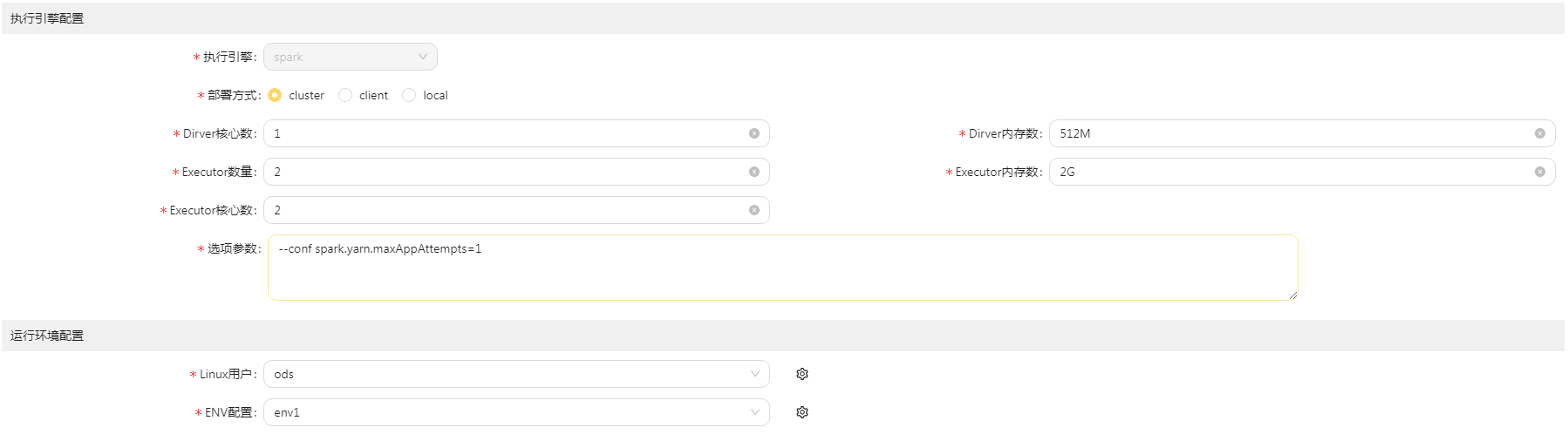
注意事项
- 如果想要使用
Spark引擎,那么需要把Datavines部署在能执行spark-submit的服务器上 - 需要配置可以执行
spark-submit的服务器用户 和 环境配置- 服务器用户指的是
root、hadoop、ods等等这些服务器创建的用户 - 环境配置指的是 在服务器上 export 的各种配置,比如下面的SPARK_HOME2
export SPARK_HOME2=/usr/hdp/2.6.3.0-235/spark-2.4.8-bin-hadoop2.7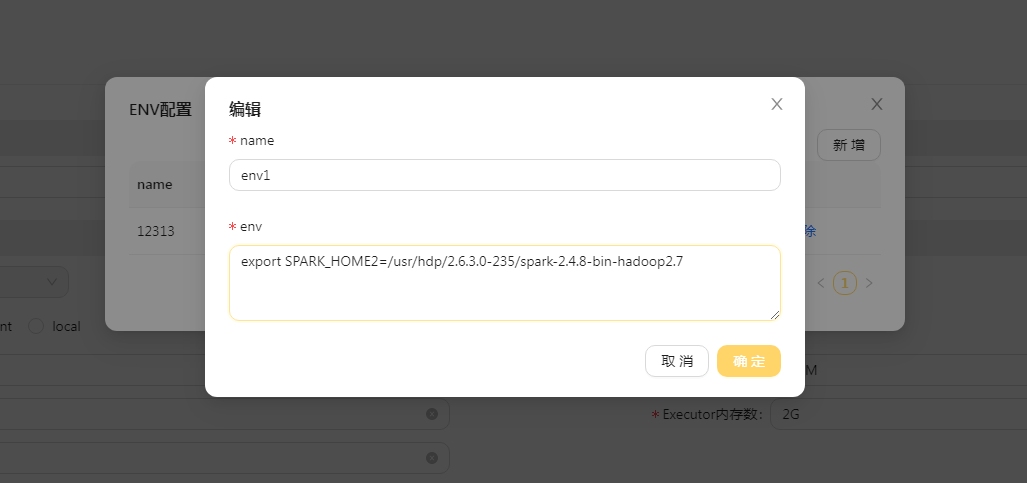
- 服务器用户指的是
- 需要在全局配置那里进行yarn配置的修改
- standalone 模式
yarn.mode=standalone
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s #第一个%s需要被替换成yarn的ip地址
yarn.resource.manager.http.address.port=8088 - ha 模式
yarn.mode=ha
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s
yarn.resource.manager.http.address.port=8088
yarn.resource.manager.ha.ids=192.168.0.1,192.168.0.2
- standalone 模式